
Building ChewSense - Using Motion Data For An On-Device AI Health Agent
This article traces how ChewSense evolved from early experiments with raw AirPods motion signals into a structured pipeline for session collection, video-assisted labeling, feature extraction, model training, and on-device inference. The core lesson is that the hardest part of applied ML was not just training a model, but building the surrounding system needed to collect trustworthy data, preserve feature parity, and make runtime behavior believable.
I did not build ChewSense in a straight line, and I definitely did not build it efficiently.
What I built, especially at the beginning, was a chain of experiments that kept circling the same question from different angles: could I use motion data from AirPods to detect chewing in a way that was actually useful? That question stayed pretty consistent, but almost everything around it changed. The app names changed, the architecture changed, the scope changed, and my idea of what mattered changed too.
At first I thought this was going to be a model problem. Get the right signals, train something smart, export it, and then I would be most of the way there. That was not really true. The longer I worked on it, the more I realized the hard part was everything around the model: collecting good sessions, syncing motion with video, labeling data in a way I could trust later, deciding what not to build, and getting the on-device pipeline to match the training pipeline closely enough that the results meant anything.
That shift in understanding is probably the real story of this project.
I started by trying to prove the sensors were even worth using
The earliest version of this work was very close to the hardware. I was recording motion and audio, looking at raw traces, and trying to get comfortable with the signal itself. At that point I was not building a real product. I was mostly trying to answer smaller questions first.
Can I read the motion data reliably?
Can I record it in real time?
Can I look at it and develop any intuition for what is happening?
Can I collect more than one modality at once without the whole thing turning brittle?
That phase was useful, but it was also the beginning of one of my recurring mistakes, which was treating optional complexity like progress. I was exploring motion and audio together, thinking about a bunch of sensing paths at once, and leaving the door open to all kinds of possibilities before I had really earned that breadth. Some of that exploration helped, but some of it was just me making the project bigger because I had not yet learned which constraints were actually helpful.
Still, I do not think that early phase was wasted. It taught me something important that shaped the rest of the project: if you spend time with raw signals early, you make better decisions later. You stop treating the data as an abstraction and start treating it like a material with quirks.
Then I started framing it like a product before I had really built the system
Once the project had a name and a clearer concept, it started looking more like an app idea and less like a sensor experiment. That was the Hows My Eating phase, and in some ways it was useful because it forced me to articulate why any of this should exist in the first place.
I was no longer just asking whether AirPods motion data could be read. I was asking whether it could support something like chew counting, pace detection, or behavior feedback around eating. That made the project more legible, but it also revealed another thing I tend to do when I get interested in a problem: I widen the ambition faster than the underlying system deserves.
At different points I was thinking about audio, accelerometer data, synchronized video as ground truth, chew counting, pace classification, maybe custom hardware, maybe desktop tools, maybe more advanced labeling flows. Looking back, a lot of that was me trying to solve the whole category instead of solving the next real bottleneck.
I do not say that as self-criticism for the sake of it. I think this is actually one of the main lessons from the project. Early on, I was still learning the difference between a broad concept and a buildable system. A concept can afford to include everything. A real system has to start saying no.
The project became real once I started collecting sessions instead of just streams
The first major change was when I moved from just capturing sensor data to building something that treated recordings as sessions. That was a much bigger step than it sounds.
Once I was recording AirPods motion alongside video, the project changed shape immediately. Now I had to care about synchronization, storage, export, review, and whether a session was complete enough to be useful later. The moment video entered the loop as ground truth, I was no longer just collecting data. I was building the first version of a dataset.
That also changed what “working” meant. Before that, working meant I could see the signal. After that, working meant I could trust the session enough to use it again. Those are very different standards.
I think this was the point where the project stopped being an interesting technical experiment and started becoming an ML workflow, even if I did not fully appreciate that yet.
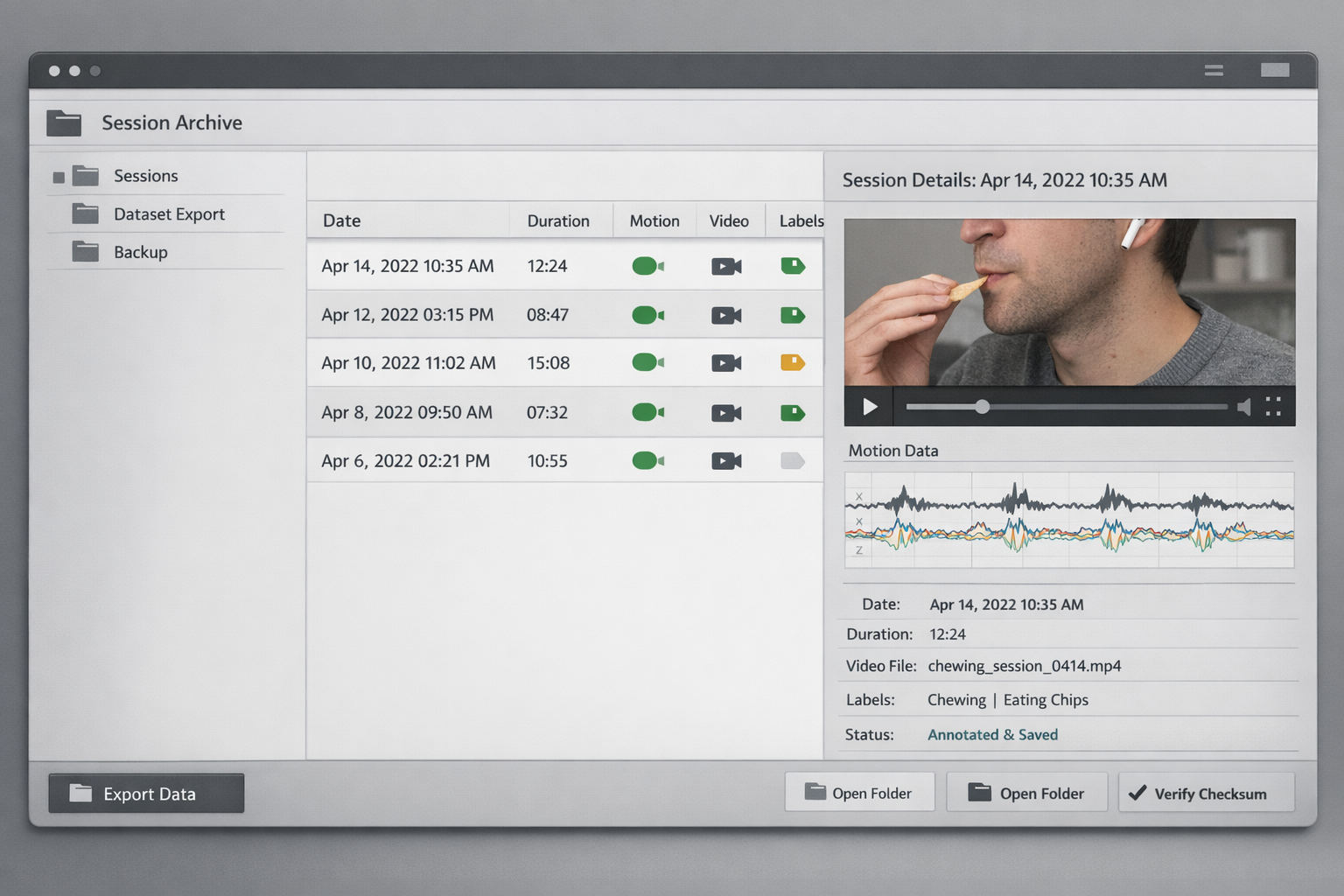
Labeling turned out to be one of the real projects inside the project
This was probably one of the most important things I learned.
It is very easy to say, at a high level, that video can provide ground truth for motion data. That sounds clean when you say it quickly. In practice, it turns into a whole operational problem. You need imports, validation, synchronization checks, labeling rules, export formats, and enough structure that you can come back later and still believe your own dataset.
I ended up building and exploring multiple labeling paths, including app-based flows, Python workflows, and even desktop-oriented ideas. At first that sounds like overkill, and some of it probably was. But it also reflected a real problem: once I had synchronized motion and video, labeling became one of the hardest parts of the entire system.
This is where I started learning more serious tradeoffs.
I learned that building everything from scratch is usually less impressive after the third week than it sounds on day one. Native systems and simpler file-based workflows often get you farther, especially when the job is not to invent a novel interface but to preserve data integrity. I also learned that labeling is not just support work. In a project like this, labeling shapes the dataset, the model, and the product direction at the same time.
Every time the labeling workflow changed, the project changed with it.

I spent a while exploring too many branches, but that taught me what to narrow
By 2025 there were clearly parallel branches in the work. Some of them were directly useful, and some of them were me still learning where the boundary of the project should be.
I explored video-based and landmark-assisted approaches, Python pipelines for parsing and review, smaller prototype apps, more product-like recorder designs, and different ways to organize sessions and metadata. From the outside that might look messy, and it was messy, but it was also how I learned what the project actually needed.
One of the strongest lessons from that phase was that the final runtime model did not need to carry all of the complexity that the development process needed. Video turned out to be incredibly valuable for collection, validation, and labeling, even if the model itself was going to lean much more heavily on motion. That distinction mattered a lot.
I also learned something more encouraging on the modeling side: motion-data models for this kind of problem do not need to be huge. Once I had a cleaner feature pipeline, it became clear that a relatively small model could plausibly do useful work here. That changed my expectations. I stopped thinking in terms of bigger models and started thinking much more about better sessions, better labels, and better feature parity between training and inference.
That was a healthier way to think about it.
The collector became better when I stopped pretending it needed to be the final product
One of the more useful turning points was when the data collection app got more disciplined and more honest about what it was.
Earlier versions were still carrying some product-story weight. Later versions were much more comfortable being research and dataset tools. They recorded synchronized video and motion, stored files in a way I could inspect, supported labeling, handled export, and paid more attention to data integrity. That clarity helped a lot.
I think I had been blending two jobs together for too long: building the thing that collects trustworthy data, and building the thing a user would eventually experience as a product. Those are related, but they are not the same. Once I stopped forcing them into the same shape, the project got better.
This is where I also learned to appreciate more native approaches. File-system-based organization, direct CSV storage, simpler review paths, and more explicit session folders ended up being more useful than trying to make the whole thing feel abstracted and product-like too early. In this case, native systems were not a compromise. They were part of what made the pipeline more believable.
The ML pipeline finally gave the project a backbone
Once the collection and labeling story got stronger, the modeling work became much more grounded.
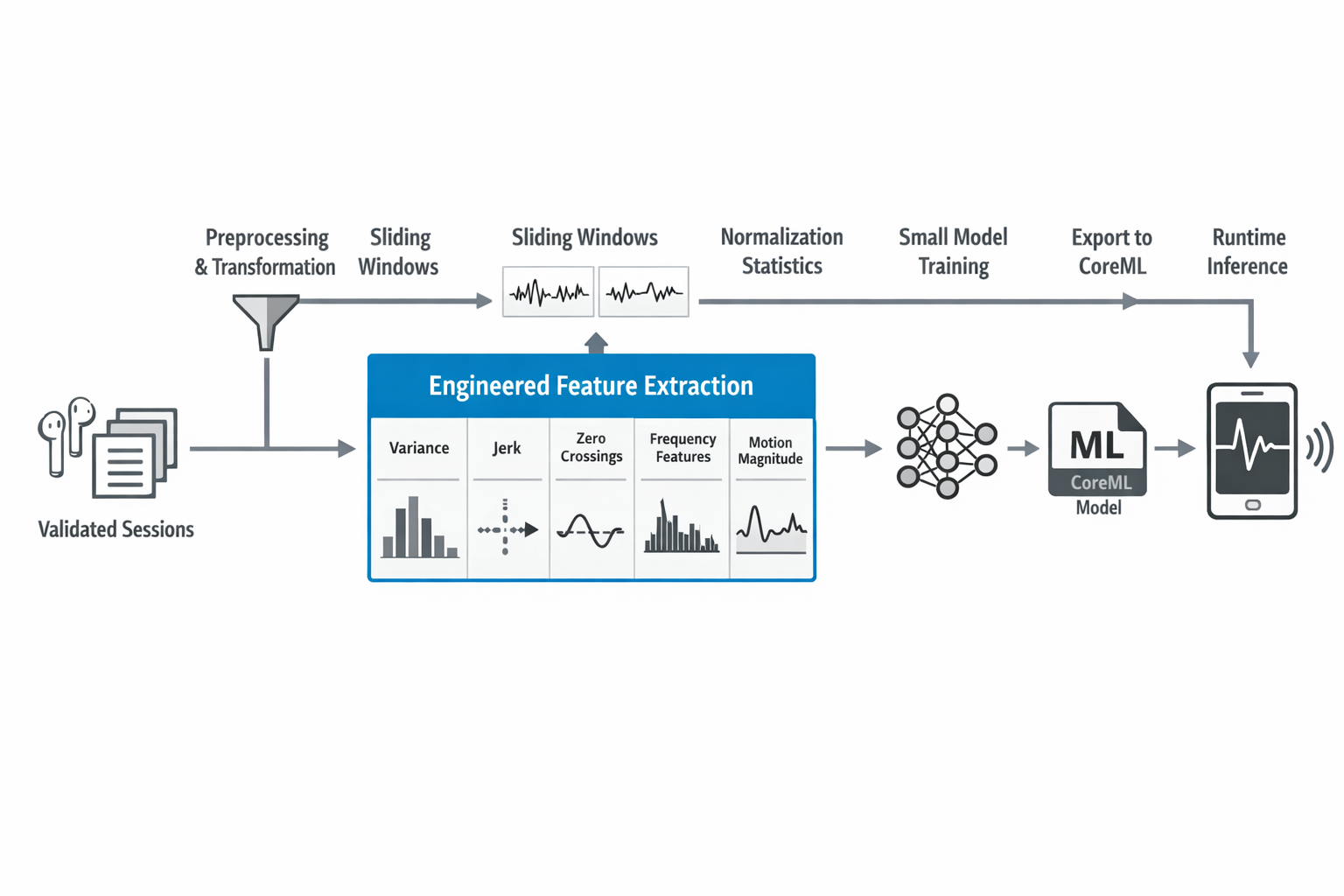
The pipeline became much more explicit: validate and transform the data, extract features from sliding windows, train a small model, export normalization stats, convert to CoreML, and test the result in an on-device setting. That kind of narrowing was hard-earned. Earlier versions of the project had lots of possible sensing ideas. This was the point where I started saying: these are the inputs, this is the feature set, this is the model, and this is the path to deployment.
That felt like progress, but not because it was flashy. It felt like progress because it was constrained.
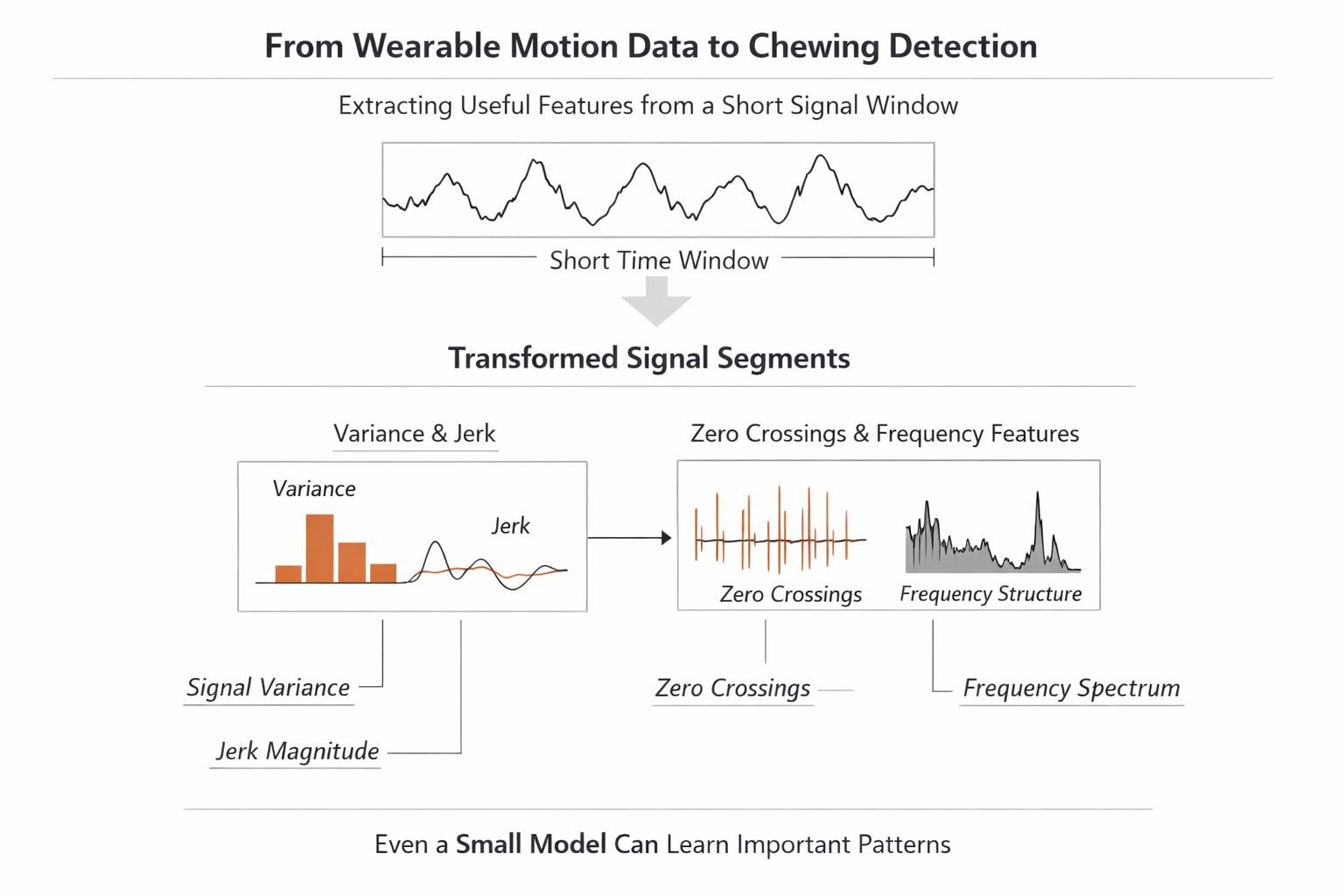
I also learned a lot here about the science of jaw and eating motion, or at least enough to stop treating it casually. Temporal windows mattered. Signal magnitude by itself was not enough. Variance, jerk, zero crossings, and frequency-related information all helped tell a more meaningful story about what was happening. The model was small, but the feature design carried a lot of the intelligence.
That was another useful lesson. A lot of the work in practical ML is not choosing a complicated model. It is understanding the phenomenon well enough to represent it cleanly.

On-device inference was where the project got honest again
Getting the model into a live app was one of the most satisfying parts of the project, but it was also where some of the remaining problems became impossible to ignore.
The debugging app did not exist to look polished. It existed so I could run the loop end to end and see what actually held up. It loaded the model, extracted features on device, applied normalization, ran inference continuously, and used smoothing and thresholds to decide whether chewing was happening.
That last part mattered more than I expected. A raw probability stream is not a product. It flickers, hesitates, and behaves like a model output. To make it feel usable, I had to think about state transitions, hysteresis, smoothing, and what kind of behavior a user would actually interpret as stable.
The debugging app also exposed one of the clearest remaining gaps: the on-device feature extraction did not yet perfectly mirror the Python training pipeline. Some of the frequency-based features still needed fuller implementation on the Swift side. That is the kind of issue you can ignore for a while if you stay in notebooks and exports, but not if you run the system live.
So in a strange way, the debugging app was valuable because it stopped me from lying to myself. The model had been trained. The model had been exported. But deployment is not real just because a CoreML file exists. It is real when the runtime path matches what the model expects closely enough that the behavior means something.
I needed that reminder.
What is working now, and what is still not there yet
What is working is the core stack.
I have a data collection workflow that is much more mature than the earliest versions. I have a clearer labeling path. I have a structured ML pipeline. I have a small model that can run on device. I have a debugging loop that lets me see the whole system behave in real time. That is real progress, and I trust it more because it came out of multiple failed or overcomplicated versions.
What is still not there yet is the final product shape.
The consumer-facing shell is still behind the infrastructure. The Swift-side runtime still needs full feature parity with the Python pipeline. The dataset still needs to get broader and more rigorous. The evaluation story needs to get stronger too, especially if I want to talk about the model as stable instead of just promising.
So I do not think this project is finished, but I also do not think it is vague anymore. It is past the stage of being just an interesting idea. It has a real workflow, a real model path, and a real on-device loop. What it needs now is less invention and more tightening.
What I think I actually learned from building this
I learned that I tend to overbuild early, especially when a problem is interesting enough to support multiple plausible directions.
I learned that native systems are often better than custom abstractions when the real goal is reliability.
I learned that labeling and data quality are not side quests. They are the work.
I learned that motion-data models can stay small and still be useful, which shifts the challenge toward signal understanding, feature design, data coverage, and runtime consistency.
I learned a lot more about the motion patterns involved in jaw movement and eating than I knew when I started, and that changed the way I thought about the whole project. The sensor signal is not magic, but it is also not arbitrary. There is enough structure there to do something real with, if the surrounding system is disciplined enough.
And I learned that building something like this is less about one app getting steadily better and more about a set of tools slowly learning how to work together: collector, labeler, transformer, trainer, exporter, and runtime debugger.
That is the version of the project I trust now.

Where I want to take it next
The next step is not to make it look more finished than it is. The next step is to make the current system more trustworthy.
That means collecting more sessions, widening the dataset, tightening evaluation, finishing the bridge between Python and Swift, and only then giving the end-user app the kind of polish it actually deserves. I still want the final product layer, but I do not want to use design to hide uncertainty in the pipeline underneath it.
So that is where ChewSense stands for me right now. It started as a curiosity about whether AirPods motion data could tell me anything useful about eating, and it turned into a much broader lesson in applied ML, data workflows, native tooling, and the cost of solving problems in the wrong order.
I am still working on it. More is coming. But this is the first version of the project that feels like it has earned its next step.
I am still refining ChewSense, so the repos are the clearest way to see what is real, what is evolving, and what comes next. If you have built something similar, want to compare notes, or just want to follow the project, reach out on LinkedIn, explore the work on GitHub, or start with these repos: ChewSense-Collection, ChewSense—Data-Collection-and-Labeling, and Chew-Sense. More context on my broader work is at zachary-sturman.com.
Keep reading
More from the portfolio
Related and recent articles
How I Sync My Portfolio Using Notion
How a portfolio can be built as a publishing pipeline, with Notion as the source of truth, n8n creating a JSON handoff, Python scripts normalizing content and media, and Next.js exporting the final static site. The result is a cleaner separation between editing, transformation, and publishing, making the site more predictable and maintainable.
April 8, 2026
The Art of Turning a 90-Minute Task Into a 2-Month Automation Project
The article traces the evolution of four systems - Obsidian + Project Management App, OPE, RPOVault, and Folio - built to keep project metadata, files, and a public portfolio in sync without constant duplication. Each version clarified the value of structured project records, but also exposed the growing maintenance cost of owning every layer, especially around files, media, and editing workflows. The final takeaway is that integrating existing tools like Notion, n8n, GitHub Actions, and Firebase solves the real problem more effectively than continuing to maintain a complex custom application.
April 8, 2026
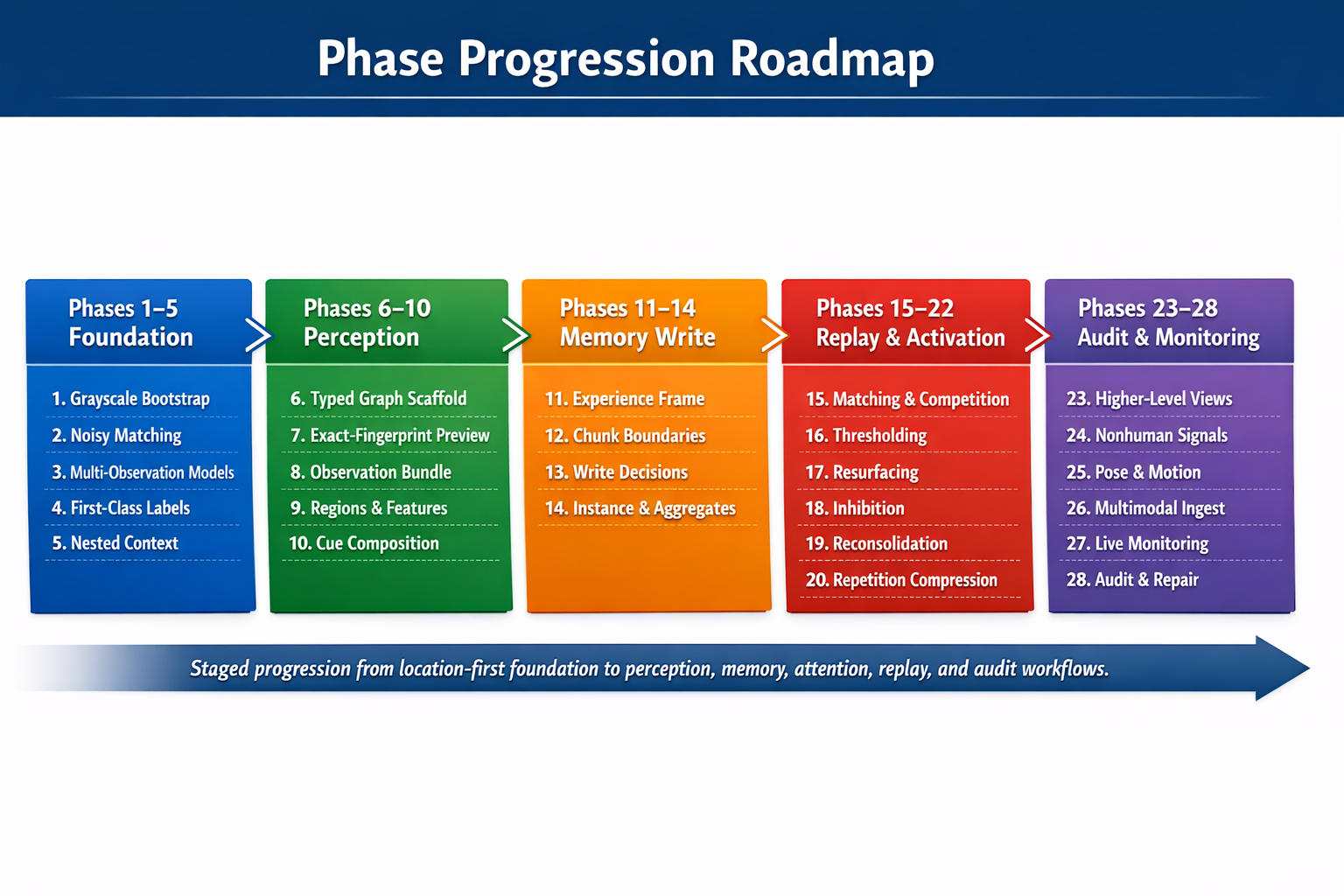
Building a Location-First Learning Agent to Explore Context, Memory, and Consciousness
This explores the idea that recognition comes more from place, context, and repeated reinforcement than detached labels, using an inspectable Python CLI agent that learns locations from sensor observations and stores state plainly. It evolves from simple grayscale location memory into richer, modality-neutral location and concept structures, with a roadmap toward broader memory processes like activation, replay, resurfacing, and reconsolidation.
April 4, 2026
Automating Linear From Notion
A bidirectional sync engine that keeps Notion and Linear aligned by normalizing their data into shared models, reconciling meaningful changes, and preserving relationships and identity across systems.
March 25, 2026
Projects connected to this article

ChewSense
ChewSense is an iOS app that helps people slow down while they eat and pay more attention to their habits. It uses the motion sensors in AirPods to pick up chewing—mainly through X-axis acceleration—and gives gentle alerts when someone might be eating too fast. The app records motion and optional video so it can learn a person’s eating pattern and adjust over time. The goal is simple: improve digestion, avoid overeating, and make meals feel more mindful without asking the user to track anything manually.

Episodic Memory Agent
An event-segmented episodic memory agent designed to simulate how an intelligent system perceives, interprets, and organizes experience over time. The architecture centers on a strict cognitive loop—resolving location, identifying entities, detecting change—and freezing those moments into structured episodes. Built with swappable modules, strict invariants, and full logging, the system prioritizes learning over hardcoded assumptions, user-defined semantics over predefined categories, and reproducible behavior over opaque heuristics.
MediLedger
MediLedger is designed around a simple idea: most of what you need to do with your medication shouldn’t require opening an app. With interactive widgets, you can log a full or half dose, check how many pills you have left, see when your refill is coming up, and set up different widgets for different medications. The app handles both prescription and non-prescription meds, tracks strength and dosage, and keeps a full history of what you’ve taken. Everything syncs through SwiftData across iPhone, iPad, and Mac, and it works offline when it needs to. You can customize what each widget shows, set up alerts for refills, and rely on automatic calculations to keep your supply accurate without any extra effort.
Train of Thought Agent
I’m using this project to test whether memory and recognition should begin with location and context instead of detached labels. Right now it is a plain, inspectable learning system that can take simple observations and file-backed sensor inputs, learn names, keep aliases and nested context straight, and show its state instead of hiding it. That makes it useful less as a finished product and more as a research tool and portfolio case study for technically curious readers, AI builders, and engineers who care about systems they can trace, correct, and inspect. What makes it distinct is the combination of restraint and ambition: it stays grounded in user or sensor evidence, it is careful not to pretend temporary sensing shortcuts are full perception, and it keeps a clear path toward a broader memory-and-attention engine. There is still real uncertainty around the final product shape, because the long-range memory system is mostly roadmap while the current learning loop is real and working. The overall character is thoughtful, methodical, and a little provisional on purpose, more like a careful research notebook than a polished AI launch.